
Golden Ratio calculated to 2 trillion digits, on Ubuntu, in the Cloud

Dustin Kirkland
on 10 August 2015
Tags: cloud , Juju , Ubuntu Core
The Golden Ratio is one of the oldest and most visible irrational numbers known to humanity. Pi is perhaps more famous, but the Golden Ratio is found in more of our art, architecture, and culture throughout human history.
I think of the Golden Ratio as sort of “Pi in 1 dimension“. Whereas Pi is the ratio of a circle’s circumference to its diameter, the Golden Ratio is the ratio of a whole to one of its parts, when the ratio of that part to the remainder is equal.
Visually, this diagram from Wikipedia helps explain it:
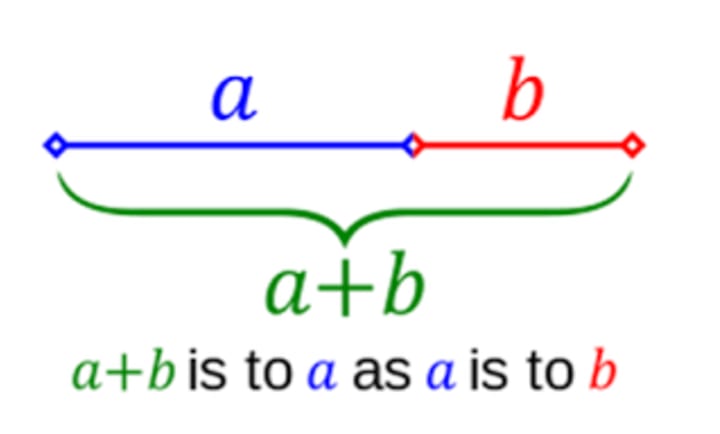


Leonardo da Vinci used the Golden Ratio throughout his works. I’m told that his Vitruvian Man displays the Golden Ratio…

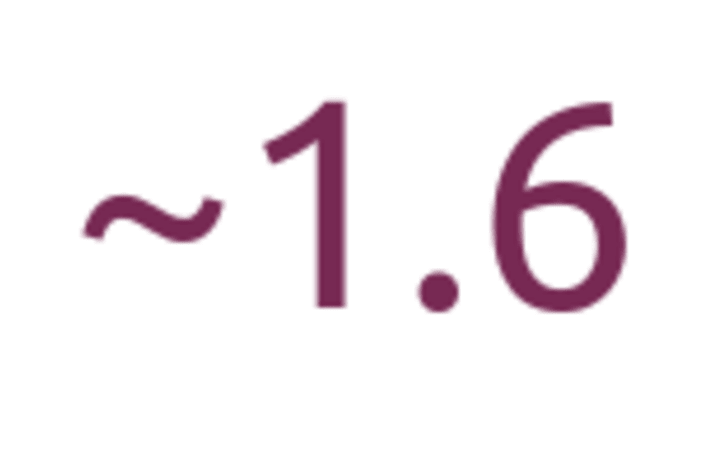

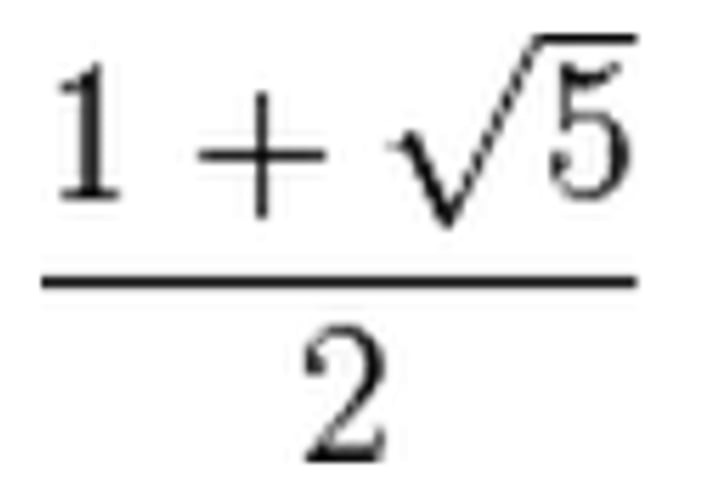

I came across y-cruncher a few weeks ago when I was working on the mprime post, demonstrating how you can easily put any workload into a Docker container and then produce both Juju Charms and Ubuntu Snaps that package easily. While I opted to use mprime in that post, I saved y-cruncher for this one 🙂
Also, while doing some network benchmark testing of The Fan Networking among Docker containers, I experimented for the first time with some of Amazon’s biggest instances, which have dedicated 10gbps network links. While I had a couple of those instances up, I did some small scale benchmarking of y-cruncher.
Presently, none of the mathematical constant records are even remotely approachable with CPU and Memory alone. All of them require multiple terabytes of disk, which act as a sort of swap space for temporary files, as bits are moved in and out of memory while the CPU crunches. As such, approaching these are records are overwhelmingly I/O bound — not CPU or Memory bound, as you might imagine.
After a variety of tests, I settled on the AWS d2.2xlarge instance size as the most affordable instance size to break the previous Golden Ratio record (1 trillion digits, by Alexander Yee on his gaming PC in 2010). I say “affordable”, in that I could have cracked that record “2x faster” with a d2.4xlarge or d2.8xlarge, however, I would have paid much more (4x) for the total instance hours. This was purely an economic decision 🙂

- 8x Intel Xeon CPUs (E5-2676 v3 @ 2.4GHz)
- 60GB of Memory
- 6x 2TB HDDs
First, I arranged all 6 of those 2TB disks into a RAID0 with mdadm, and formatted it with xfs (which performed better than ext4 or btrfs in my cursory tests).
$ sudo mdadm --create --verbose /dev/md0 --level=stripe --raid-devices=6 /dev/xvd?
$ sudo mkfs.xfs /dev/md0
$ df -h /mnt
/dev/md0 11T 34M 11T 1% /mnt
Here’s a brief look at raw read performance with hdparm:
$ sudo hdparm -tT /dev/md0
Timing cached reads: 21126 MB in 2.00 seconds = 10576.60 MB/sec
Timing buffered disk reads: 1784 MB in 3.00 seconds = 593.88 MB/sec
The beauty here of RAID0 is that each of the 6 disks can be used to read and/or write simultaneously, perfectly in parallel. 600 MB/sec is pretty quick reads by any measure! In fact, when I tested the d2.8xlarge, I put all 24x 2TB disks into the same RAID0 and saw nearly 2.4 GB/sec read performance across that 48TB array!
With /dev/md0 mounted on /mnt and writable by my ubuntu user, I kicked off y-crunch with these parameters:
Program Version: 0.6.8 Build 9461 (Linux - x64 AVX2 ~ Airi)
Constant: Golden Ratio
Algorithm: Newton's Method
Decimal Digits: 2,000,000,000,000
Hexadecimal Digits: 1,660,964,047,444
Threading Mode: Thread Spawn (1 Thread/Task) ? / 8
Computation Mode: Swap Mode
Working Memory: 61,342,174,048 bytes ( 57.1 GiB )
Logical Disk Usage: 8,851,913,469,608 bytes ( 8.05 TiB )
Byobu was very handy here, being able to track in the bottom status bar my CPU load, memory usage, disk usage, and disk I/O, as well as connecting and disconnecting from the running session multiple times over the 4 days of running.

Start Date: Thu Jul 16 03:54:11 2015
End Date: Sun Jul 19 11:14:52 2015
Computation Time: 221548.583 seconds
Total Time: 285640.965 seconds
CPU Utilization: 315.469 %
Multi-core Efficiency: 39.434 %
Last Digits:
5027026274 0209627284 1999836114 2950866539 8538613661 : 1,999,999,999,950
2578388470 9290671113 7339871816 2353911433 7831736127 : 2,000,000,000,000
Amazing, another person (who I don’t know), named Ron Watkins, performed the exact same computation and published his results within 24 hours, on July 22nd/23rd. As such, Ron and I are “sharing” credit for the Golden Ratio record.

Look at the above chart of records, which are published on the y-cruncher page, the vast majority of those have been calculated on physical PCs — most of them seem to be gaming PCs running Windows.
What’s different about my approach is that I used Linux in the Cloud — specifically Ubuntu in AWS. I paid hourly (actually, my employer, Canonical, reimbursed me for that expense, thanks!) It took right at 160 hours to run the initial calculation (79 hours) as well as the verification calculation (81 hours), at the current rate of $1.38/hour for a d2.2xlarge, which is a grand total of $220!
$220 is a small fraction of the cost of 6x 2TB disks, 60 GB of memory, or 8 Xeon cores, not to mention the electricity and cooling required to run a system of this size (~750W) for 160 hours.
If we say the first first trillion digits were already known from the previous record, that comes out to approximately 4.5 billion record-digits per dollar, and 12.5 billion record-digits per hour!
Hopefully you find this as fascinating as I!
Ubuntu cloud
Ubuntu offers all the training, software infrastructure, tools, services and support you need for your public and private clouds.
Newsletter signup
Related posts
Meet Canonical at SPS 2024
SPS (Smart Production Solutions) 2024 is almost here! With over 1,200 national and international exhibitors, SPS is the main gathering of industrial...
Canonical and OpenAirInterface to collaborate on open source telecom network infrastructure
Canonical is excited to announce that we are collaborating with OpenAirInterface (OAI) to drive the development and promotion of open source software for open...
AI Inference on the Edge with TensorFlow Lite
This blog post dives into the world of AI on the edge, and how to deploy TensorFlow Lite models on edge devices. We’ll explore the challenges of managing...